Performance¶
You can run SimpleTensorFlowServing with any WSGI server for better performance. We have benchmarked and compare with TensorFlow Serving. Find more details in benchmark directory.
STFS(Simple TensorFlow Serving) and TFS(TensorFlow Serving) have similar performances for different models. Vertical coordinate is inference latency(microsecond) and the less is better.
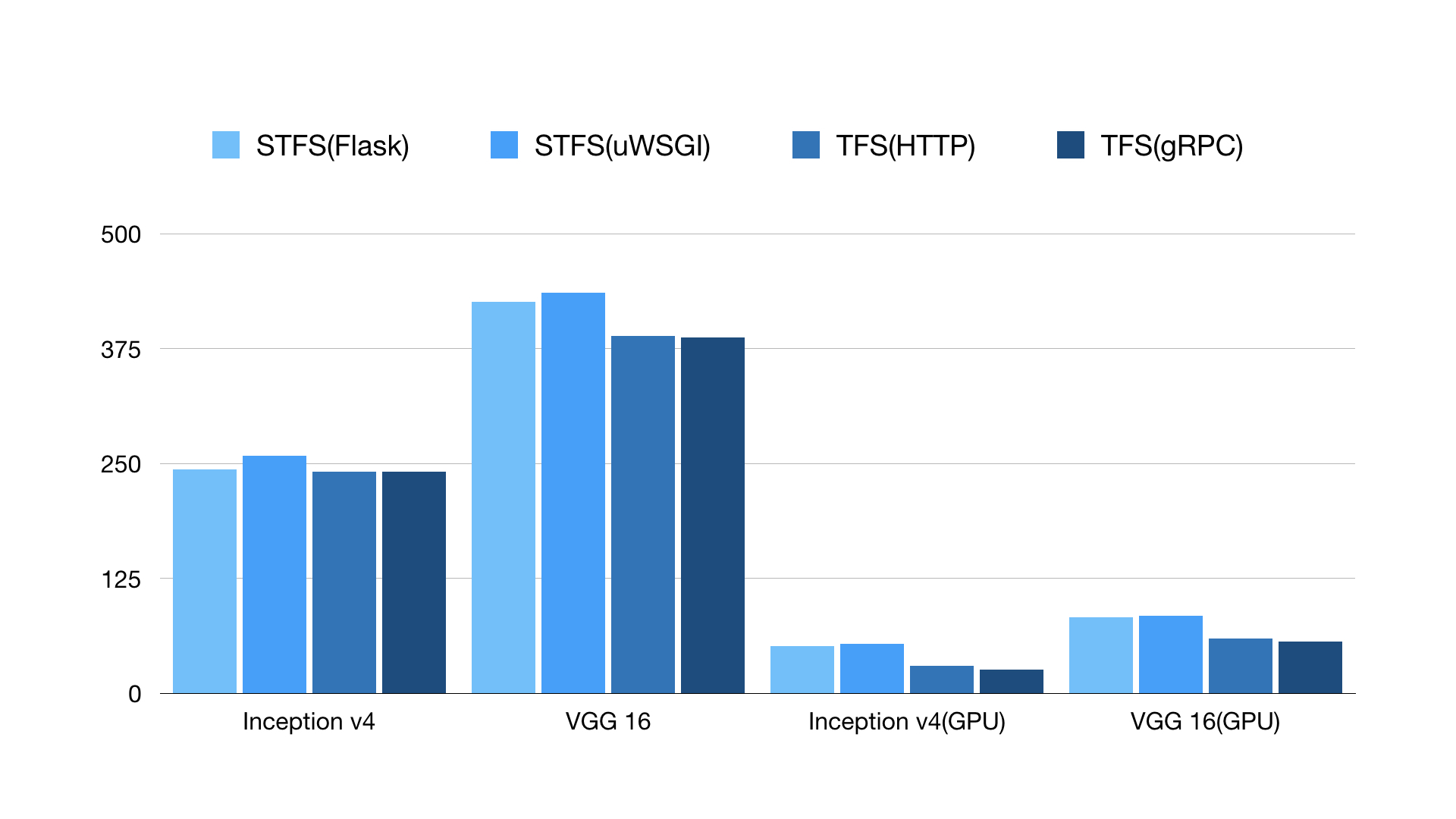
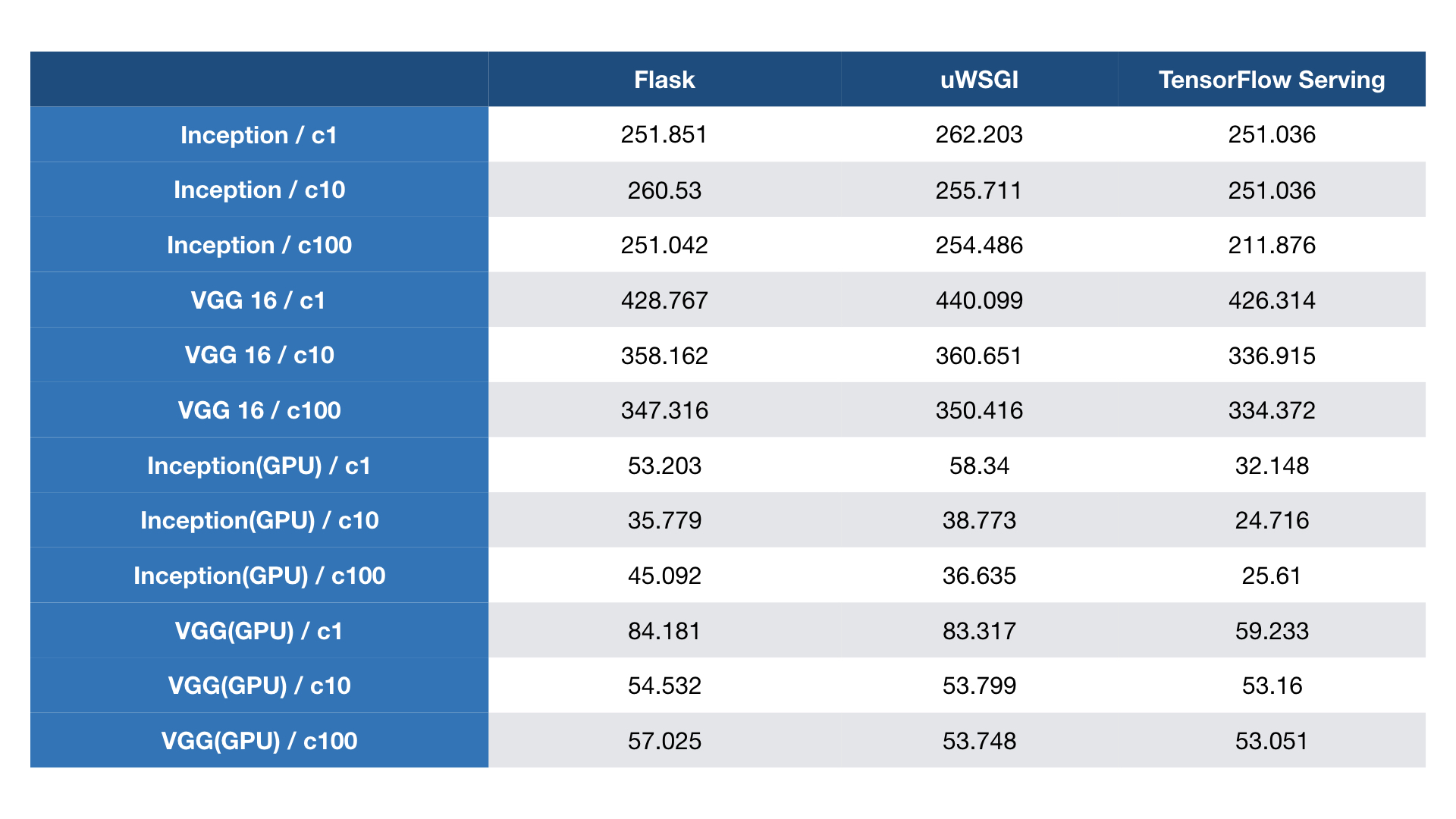
Then we test with ab with concurrent clients in CPU and GPU. TensorFlow Serving works better especially with GPUs.
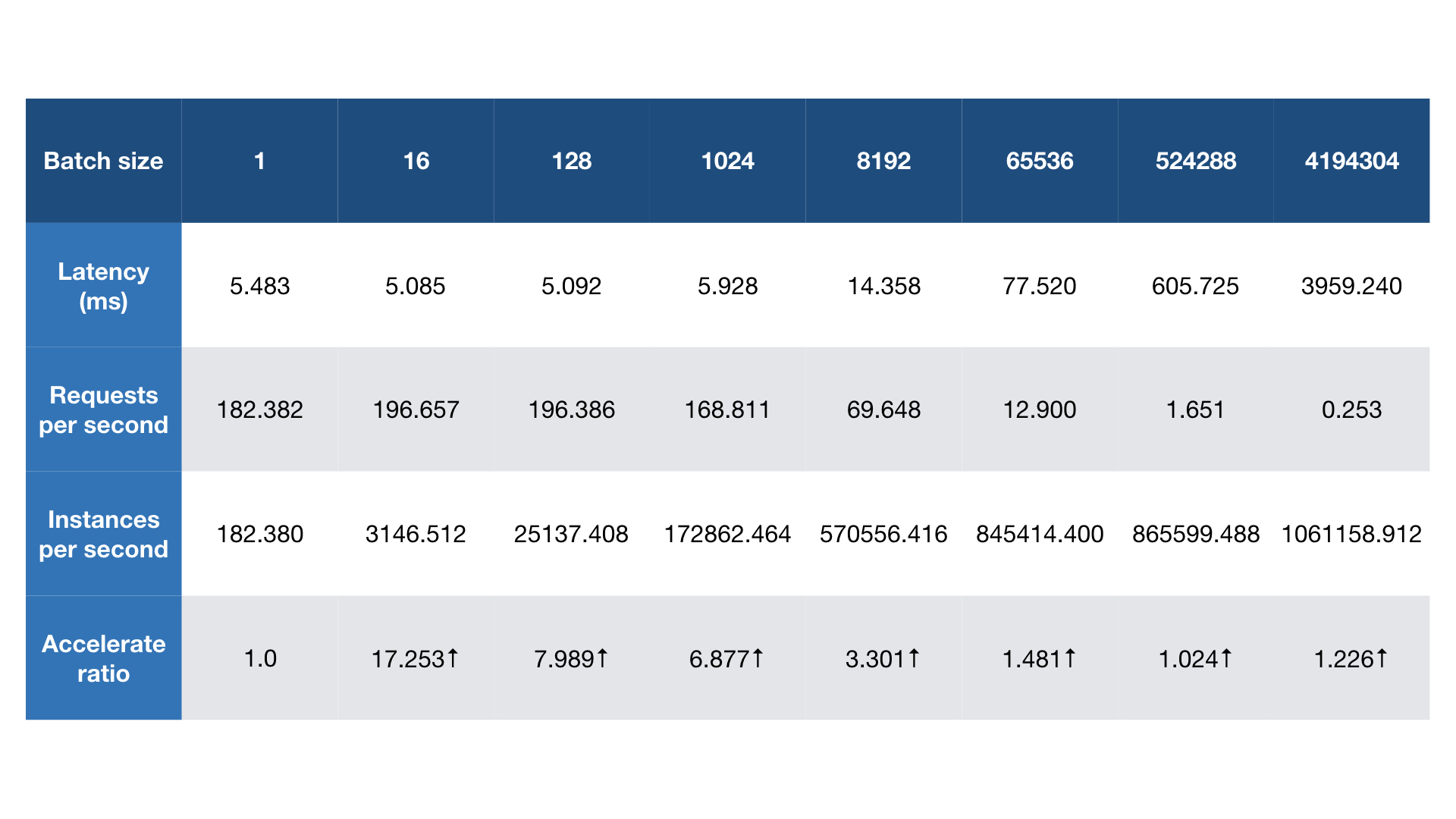
For simplest model, each request only costs ~1.9 microseconds and one instance of Simple TensorFlow Serving can achieve 5000+ QPS. With larger batch size, it can inference more than 1M instances per second.